机器学习基础入门和Python sklearn
关于机器学习的一些笔记和摘抄整理。
机器学习基础
机器学习 vs. 传统编程
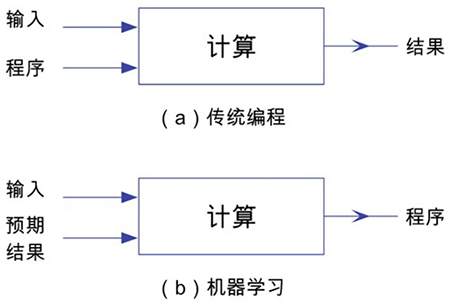
三种类别
监督学习
监督学习是根据已知的方法和规律,对新样本进行分类和预测。
监督学习就好比学生在学校学习各种知识和理论的过程。整个过程是在老师的监督下完成,所学知识的应用体现在平时的测试中,并且可以通过对比“标准”答案来不断改进和巩固学习成果,在下一次的测试中取得更好的成绩(预测效果)。根据目的不同,可以有分类和回归(预测)两种:
- 分类 —— 根据事物特征将其划分到已知的类别。
- 根据事物的特征,将新遇到的事物(新样本)归类到已知的某个类别。
- 回归(预测)—— 根据事物的特征和预测将来的发展趋势。
- 根据事物的特征和发展规律,预测将来的发展趋势。
非监督学习
非监督学习与监督学习正好相反,在过程中并不清楚有哪些特征标签,而是通过对样本的观察、分析和总结,去发现其中的特征,从看似杂乱无章的数据中发现共性。然后对新样本进行归类。
归类/聚类(clustering)—— 对大量看似无特征的样本进行分类。
经常会说非监督学习是归类或聚类(clustering)。与分类不同,聚类在划分之前并不知道有哪些类别,以及类别的特征,而是通过对样本的各种特征进行分析,将相似的样本划分为一组,进行“物以类聚”的划分。是一个从无到有的发现过程。
半监督学习
介于监督和非监督学习之间。是基于监督学习获得理论和知识,对非监督学习的样本(无特征标签)进行分类。可以理解为我们走出学校以后根据在课堂上学到的知识和理论,对生活中遇到的事物进行分类和预测。
Python sklearn (scikit-learn)
Scikit-learn是一个用于Python的免费开源机器学习库。
三大步骤
机器学习的本质就是让机器使用特定的算法对输入数据进行类似人的智能学习(找规律),根据同样的模型对新样本进行进行预测。具体到python中的sklearn,是通过一下三大步骤实现的。
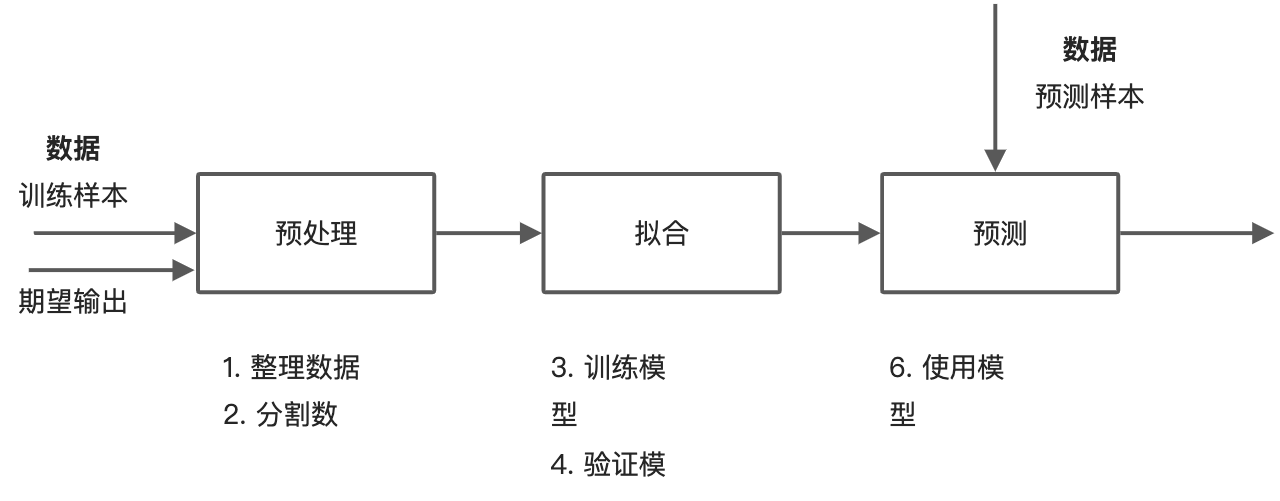
- 准备数据——对输入数据进行预处理
- 选择、训练和测试模型——使用处理后的样本数据,针对特定模型进行拟合、训练
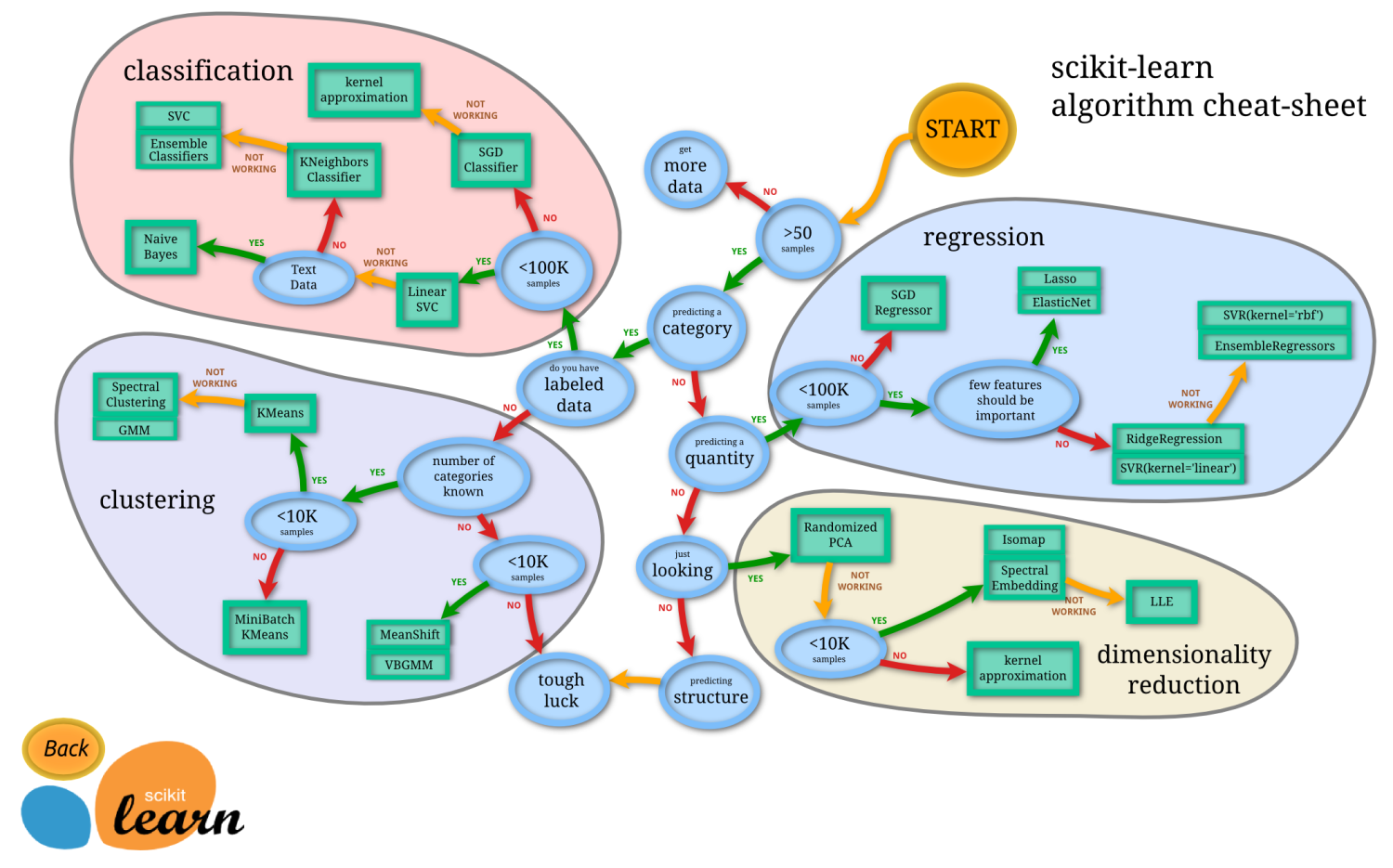
- 模型的选择,可以根据要解决的问题和使用场景,scikit-learn提供了一张图(选择正确的估计器)来详细描述模型选择的流程,最终指向机器学习的集中主要使用场景,回归、分类和聚类,以及scikit-learn提供的数据降维方法。
- 使用模型预测——使用训练后的模型对新样本进行预测,并根据预测结果过进一步优化
scikit-learn (sklearn) 实现
sklearn中内置了常用的机器学习算法和模型,以及基本的预处理方法。分别由**预测(估计)器(estimator)和预处理器(preprocessing)**实现,并且它们继承自同一个基础预测器。
转换器和预处理器
预处理器和转换器主要负责对原始数据的预处理和转换,从而消除不同数据之间的绝对差异。
1 | from sklearn.preprocessing import StandardScaler |
预测器
sklearn中提供的数十种内置机器学习算法和模型,都通过估算器提供。可以通过引入相应的估算器来使用对应的模型。
1 | from sklearn.ensemble import RandomForestClassifier |
管道
管道用来将转换器和预测器组合成一个同一的对象,表示一个完整的数据流处理过程(管道)。然后使用管道的fit和predict来进行训练和预测。同时,使用管道还可以防止数据泄露。
1 | from sklearn.preprocessing import StandardScaler # 预处理器 |
模型评估
回归算法指标
回归算法的核心思想是评估预测值和观察值之间的误差。从最原始的残差(residual)到基于残差的各种变形,以便后续的数学运算和处理。
- Mean Absolute Error 平均绝对误差:对残差做绝对值处理,避免残差正负导致的相互抵消。
- Mean Squared Error 均方误差:为了便于求导,对平均绝对误差进行平方。
- Root Mean Squared Error 均方根误差:如果目标变量的量纲保持一致,可以对均方误差进行开放。
- Coefficient of determination 决定系数:进一步去除对量纲的依赖。
分类算法指标
相比较回归算法的各种残差指标,分类算法更多的则是关注分类的精度,即预测正确的样本数量占总预测样本的比例。然后,预计不同的场景,从不同角度来看精度对结果的影响。
- Accuracy 精度:每一个分类中预测正确的样本数占总样本的比例。
- 混淆矩阵 Confusion Matrix
- 准确率(查准率) Precision
- 召回率(查全率)Recall
- Fβ Score
- AUC Area Under Curve
- KS Kolmogorov-Smirnov
关于各个指标的详细说明,可以参考知乎——机器学习评估指标。
参数搜索
所有预测器都有可以调整的参数,也叫超参数。其特指不能通过学习得到的参数。在使用各种不同模型时,需要将超参数作为参数传递给预测器。
sklearn中提供了在参数集中搜索最佳超参数的方法,其基于最佳交叉验证(CV, Cross-Validation)分数获取对应的超参数。sklearn中最简单的方法是调用cross_val_score函数。
估算器中的任意参数都可以通过参数搜索来获得最佳参数。
参数搜索的基本要素
- 参数搜索方法
- 评估方法
GridSearchCV 网格搜索方法
计算参数集中所有参数的组合。GridSearchCV通过使用param_grid参数来指定参数候选值。
例如下边的例子指定搜索两个参数候选值。通过GridSearchCV的fitting接口拟合后,会对所有候选参数进行评估,保留最优参数组合。
1 | # 选择模型 |
RandomizedSearchCV 随机搜索方法
从具有制定分布的参数空间中抽样出定量的参数候选。RandomizedSearchCV会在指定范围内,使用某个特定分布抽取参数值进行评估。用字典形式来指定参数的具体抽样范围,针对每一个参数,可以指定
- 具体的参数
- 采样分布——可以使用scipy.stats模块,其中包含了很多采样分布,如expon,gamma,uniform或者randint。
- 离散选项列表
例子
1 | # 选择模型 |
评估方法(指标)
参数搜索默认使用估计器的score函数来评估参数的设置。默认为
当然,sklearn还提供了其它一些评估函数可供不从场景使用。同时,也可以将多种评估指标结合起来使用。